
Stop Calling It Understanding - Part 2
The cell is the verifier: forward‑model mismatch, operator variance, and why proxies lie

In the previous article (Part 1) it was the end of innocence about “thinking.” In this essay (Part 2), biology is where you lose innocence about “understanding.”
Read them as a single mental model.
Part 1: the runtime is the new model.
Part 2: if you do not build the runtime correctly, biology will bankrupt you.
If you have spent real money on “AI for drug discovery,” you already know the failure pattern. The models do not fail loudly. They fail persuasively. They give you mechanistic prose, ranked hit lists, and confidence curves, and then the lab invoices arrive and nothing reproduces. The industry keeps trying to solve this by scaling models and scaling datasets as if biology were just another distribution to learn. It is not. Biology is a control problem under adversarial measurement, with capital at risk.

A cell answers you through a noisy channel. The channel hides state. It aliases causes. It injects structured interference that correlates with the proxy metrics you choose. The moment you scale hypothesis generation and selection, you create a p‑hacking machine unless you enforce integrity constraints. A high‑integrity discovery system does not “understand” biology in a mystical sense. It allocates compute to reduce the probability of wasting time, and it allocates experiments to collapse uncertainty, while explicitly modeling the fact that its own forward model is wrong.
Start with the equation that forces adult behavior by making the lab term explicit.

In biology, C_lab dominates C_infer, and it dominates in a lumpy way. A failed experiment is rarely “we lost $1,000.” It is “we lost a week.” The week is the unit of account. The week is what decides whether a program hits a milestone before runway collapses, whether an IND timeline survives, whether you walk into a board meeting with evidence instead of a story.
That economic reality makes refusal a fiduciary duty. Because it is “public money” when it comes to grants, and opportunity cost of innovation when it comes to VC capital.
A refusal gate is a policy that decides when the system is allowed to turn cheap uncertainty into expensive action.
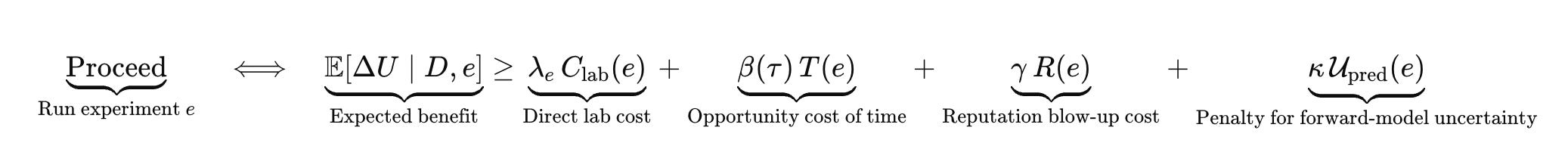
Two structural details matter.
First, the shadow price of time is not constant. It escalates as runway shrinks and milestones approach.
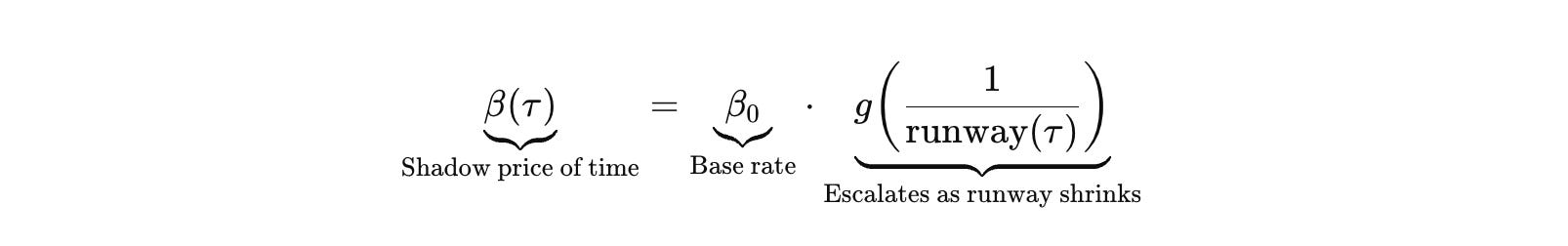
Second, the penalty term is the place where biology destroys the clean Bayesian fantasy. Most “AI for bio” failures are simulator failures in disguise. The system behaved as if it had a likelihood model when it did not.
Biology rarely gives you a trustworthy forward model for p(y ∣ e ,θ). If you substitute an LLM or a learned surrogate and treat it as ground truth, you add a hallucination layer and then optimize against it. The correct move is to make the forward model explicit, treat it as learned and imperfect, and carry uncertainty about it as part of the belief state.
Let θ represent the mechanistic hypothesis class you care about (a pathway graph, latent state dynamics, causal structure). Let ϕ represent the forward model that maps (e,θ) into an assay outcome distribution, including the measurement process and artifact structure.
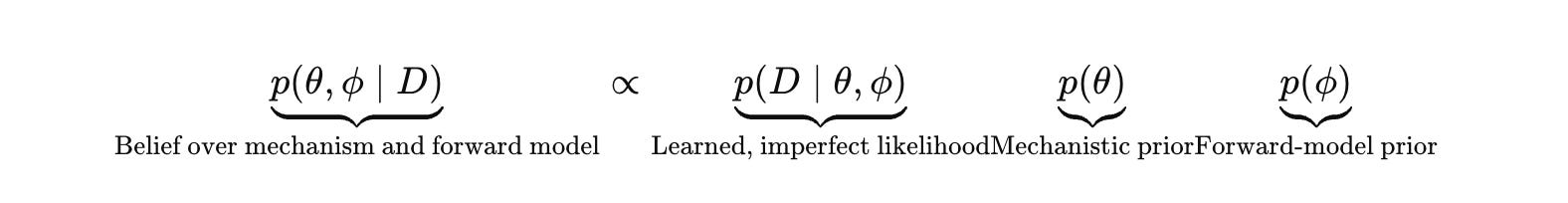
The predictive distribution that justifies action integrates over both.
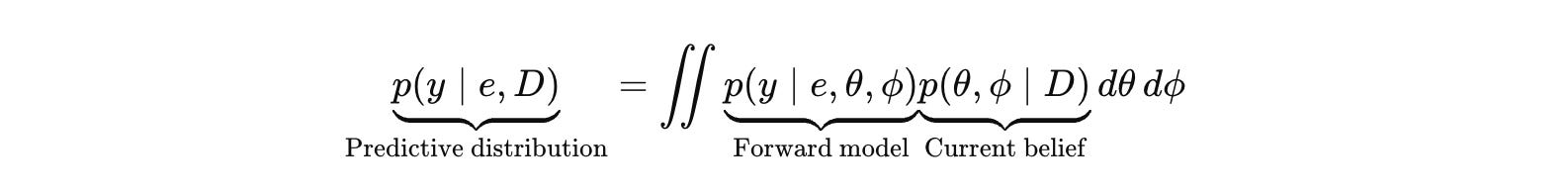
I believe that this is the operational meaning of epistemic humility. If the system cannot predict controls and negative controls in the regime it wants to query, it does not get to treat its own likelihood as evidence. The update is void. You do not get a posterior. You get a story instead.
Now model the most common way biology lies to you, through proxies.
Write the observed assay readout as true biology plus structured interference plus noise.

That artifact term is now an attack surface. Fluorescent quenchers. Auto‑fluorescent compounds that light up the plate while the cells do nothing. Luciferase interference. Detergent‑like molecules that rupture membranes and “win” a viability proxy by killing everything. Colloidal aggregators that trigger nonspecific stress programs that look like pathway modulation. If your runtime optimizes for (r), it will discover (a(e)) faster than it discovers (g(z)), because artifacts are often easier to produce than biology.
Then add the missing variable that separates “ML theory” from “lab ops.” Because data is not a platonic ideal. It is a physical residue left by a human.
If you do not model operator effects, you cannot separate biology from “Tuesday.”
Make the execution context explicit. Let (o) index operator and operational context (operator, instrument, batch, day, plate position, reagent lot).
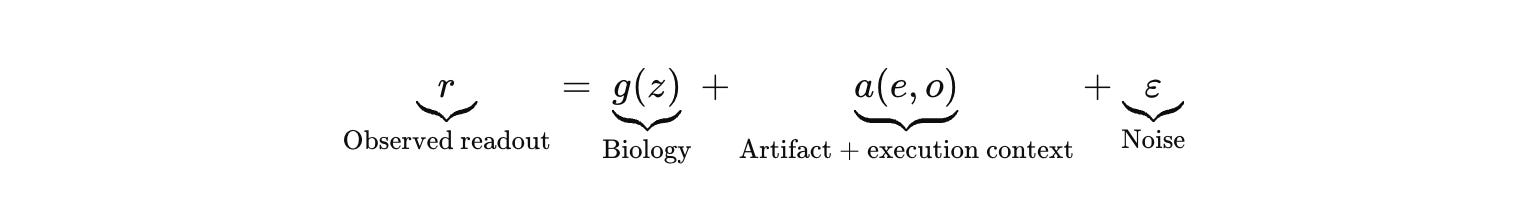
A decomposition that maps directly to the database schema you need is a random‑effects structure.

I am not doing this for academic ornamentation. It tells the engineering team what to log. It tells the platform team what features must exist in the LIMS. It tells the ML team what they are allowed to condition on if they want belief updates that survive reruns.
Now define the objective the outer loop is supposed to optimize.
Information gain is the expected reduction in uncertainty over the hypotheses you actually care about. It distinguishes “we got a hit” from “we learned.”
The correct uncertainty object includes mechanism and forward model, because in biology those two are entangled.
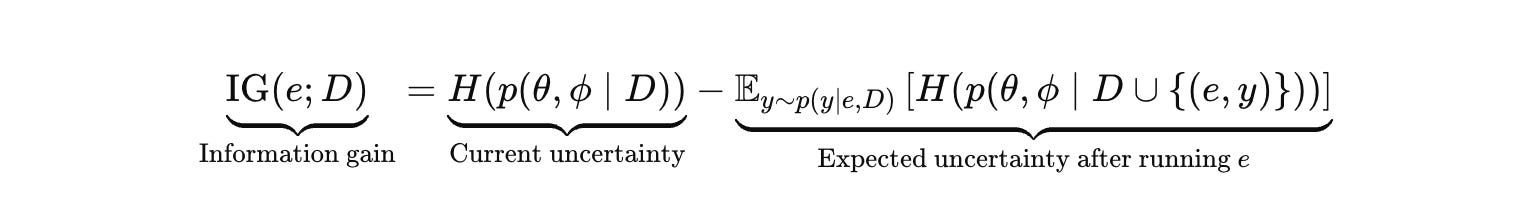
IMO, this is intractable for any interesting hypothesis space. Exact entropy integrals are notation and not computation.
Approximation is the architecture.
The workable approximation is a committee‑based active learning loop, but committee disagreement is only useful if the committee is both heterogeneous and competent. Otherwise you get two failure modes. Hallucination in unison (mode collapse) or trivial disagreement (weak models screaming and driving IG high for useless reasons.
Competence gating fixes this by silencing the idiots in the room.
Define a calibration set D_cal consisting of controls and negative controls on the relevant assay channel. Each model’s vote weight depends on predictive performance on calibration.
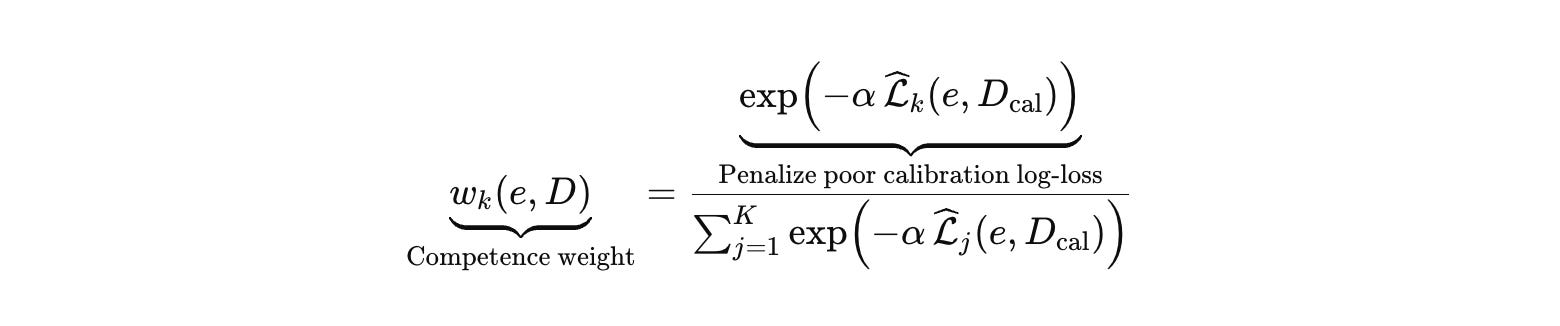
Now measure disagreement only among competent voters using a weighted Jensen–Shannon divergence.
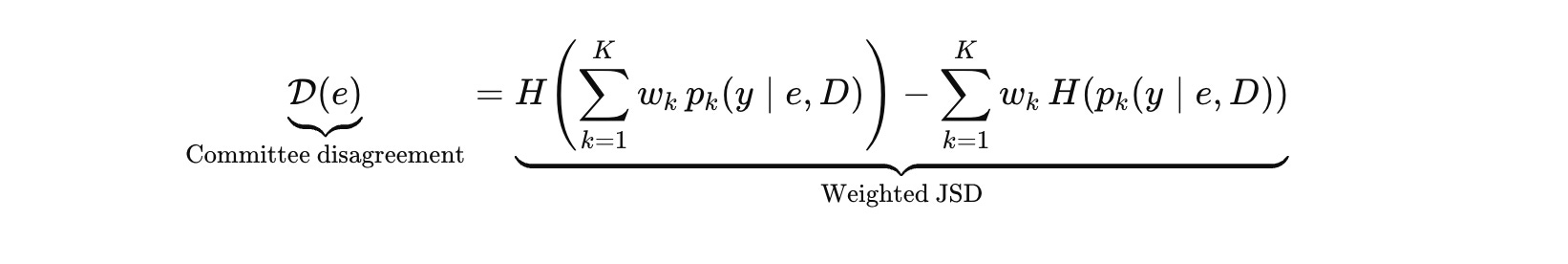
Then correct for trivial disagreement explicitly.
Trivial disagreement is disagreement caused by representational mismatch or out‑of‑regime models, not by genuine uncertainty about the world. A system that chases trivial disagreement will burn experiments to prove obvious facts.
So the approximate information gain used for experiment selection must include a penalty term.

T(e) is a catch‑all for residual triviality that you can implement concretely which includes known model‑class failure modes, disagreements driven by low‑competence voters, or disagreements occurring in assay dimensions where calibration indicates the forward model is unreliable. Disagreement counts only when the committee is both heterogeneous and calibrated on the channel you are about to pay to query.
Now we can tighten the integrity logic where most organizations bleed! selection.
Selection turns scaled hypothesis generation into a p‑hacking engine. The score you optimize contains flattering noise and confounding.
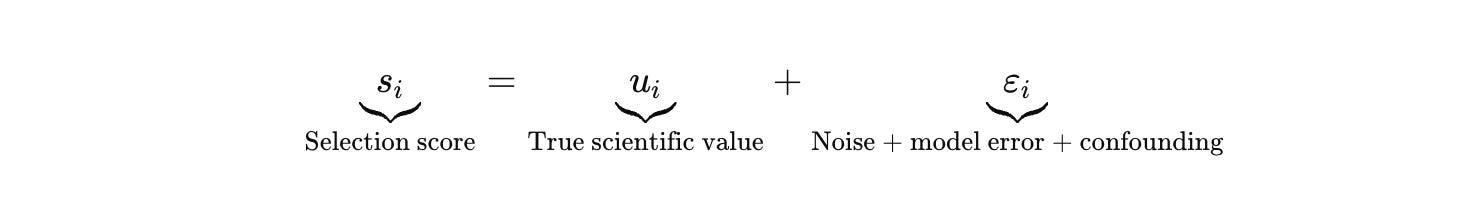
As you generate more candidates, you mine the tails of εi. Biology makes those tails ugly. It includes batch effects, plate position effects, reagent lot drift, ambient RNA and doublets, guide efficiency distributions, copy‑number artifacts, hidden contamination, operator variance. A system that “discovers” too fast is almost always discovering artifacts.
False discovery control is the constraint that prevents the engine from laundering artifacts into claims.
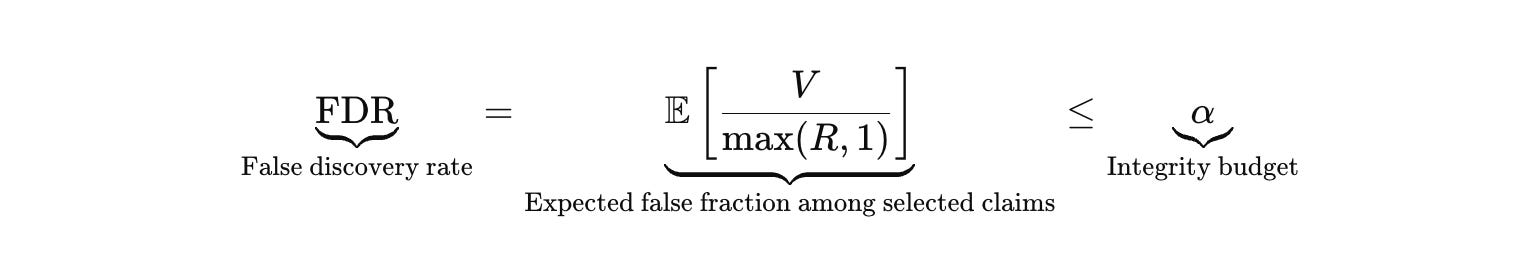
I do not believe that this is cultural hygiene. It is more of an algorithmic gate. Replication, negative controls, orthogonal assays, and counterscreens are not add‑ons. They are the acceptance path that keeps selection from becoming industrial self‑deception.
Now we can address cold start honestly, without assuming a cheap assay ladder exists.
Public priors are contaminated. Internal data is high fidelity. That remains true. But many domains do not offer a cheap, relevant calibration ladder. Sometimes the first meaningful experiment is expensive. Protein design, in vivo efficacy, complex co‑culture phenotypes, anything where the proxy that matters is the expensive thing.
So a high‑integrity engine is not “born safe.” It is born naive. It earns conservatism by paying for calibration. The correct financial framing is a calibration tranche. A deliberate allocation of early capital whose purpose is not discovery but integrity. Learning how wrong your forward model is and learning what to distrust.
You can write this as a dynamic trust weight that transitions from “trust the paper” to “trust the robot” as calibration quality improves.
Let D_low be public corpora and public datasets. Let D_high be internal measurements under your protocols, instruments, and operators.
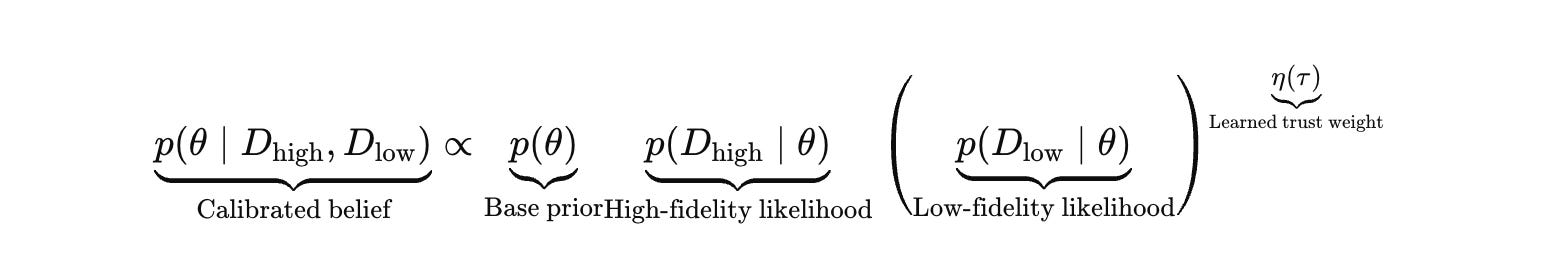
Eta starts above zero to avoid paralysis, then tightens as the system accumulates high‑fidelity calibration evidence.
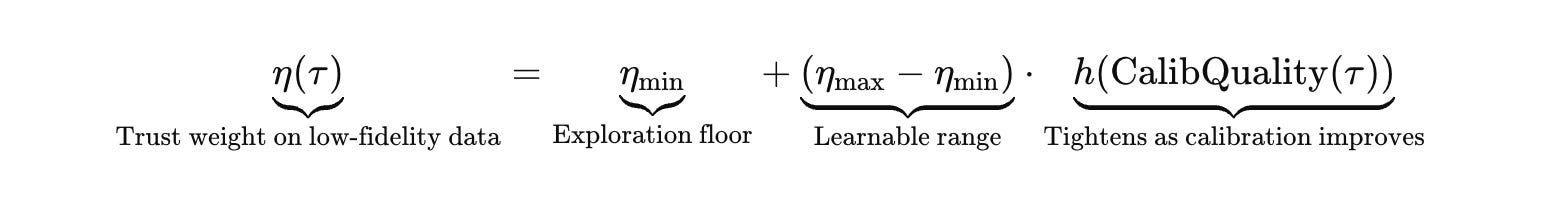
Calibration quality is concrete: can the forward model predict controls and negative controls on the actual assay channel, across operators, batches, and days. When it cannot, the system is not allowed to tighten belief or escalate. It is forced into calibration actions until the likelihood model is trustworthy enough to update.
One final layer makes the doctrine executable at the executive level.
The parameters β(τ), α (integrity budget), λ_e, γ, κ, and λ_triv are not constants of nature. They are policy choices. They encode strategy.
The executive team’s job is not to pick targets by intuition and then hope the model performs miracles. The executive team’s job is to set the shadow price of time and the integrity budget on how expensive a false claim is allowed to be, how conservative the system should become as runway decays, how much calibration tranche to allocate early, and how hard the refusal gate should bite. The engine executes that policy. IMO, that is what makes it governable.
This is possibly one of the operating logic of a high‑integrity discovery engine. Creative proposal lives upstream. Ruthless acceptance lives downstream. Refusal preserves capital. Verification preserves time. The cell remains the ultimate verifier, and the system remains humble about what it can predict before it pays to find out.
Do you have a different take? Please share.