
Stop Calling It Thinking - Part 1
Trajectory search, proxy optimization, and why argmax is the new risk surface

This ‘AI models’ essay is in two parts. Part 1 (this article) argues that we have reached the end of innocence about what we casually call “thinking.” Part 2 (next article) turns to biology, where any remaining innocence about “understanding” collapses the moment it meets real mechanisms, real constraints, and real interventions.
Read them as a single mental model.
Part 1: the runtime is the new model.
Part 2: if you do not build the runtime correctly, biology will bankrupt you.
TLDR: This is a dense, systems-and-control view of modern AI, not a generic “LLMs can reason” take. In this article, I argue that what people call “reasoning” is a budgeted runtime algorithm, candidate generation plus selection plus verification plus tool calls, governed by compute and risk. It explains why scaling test-time search has sharp limits, why argmax over learned verifiers amplifies blind spots, and why tool use turns the stack into a sequential decision-maker under partial observability where errors compound.

For a while, we got away with an AI model story that was too simple. Pretrain a big model, post-train it for helpfulness, ship it, then argue about whether it “understands.” That story survives only when the interaction pattern is shallow and the human quietly pays the cost of error. The moment you push these systems into workflows with liability, latency targets, compliance boundaries, and irreversible side effects, the physics of the situation shows up. You are no longer selling a model. You are selling a controlled procedure that spends compute, calls tools, checks itself, and decides when to stop.
As I think of it, over the last 18 months (ever since the release of “Strawberry”), the first real change was economic. Training became fixed capital. Inference became variable capital, invested per request with a policy. The base model is an amortized solver. It tries to compress a distribution of tasks into weights so that the marginal cost of solving a new instance is a cheap forward pass. When you enable “reasoning,” you are admitting the compression failed for the instance you were handed, and you are choosing to pay marginal cost to explore the residual search space.

The term that matters is the last one. It used to be “one pass, one answer.” It is now an algorithm. Sample candidates. Score them. Verify them. Call tools. Retrieve evidence. Backtrack. Repeat. Inference stopped being a constant and became a budgeted search process.
If you want the cleanest representation of that shift, you write inference spend as the output of a compute allocation policy. The runtime chooses a compute budget for a prompt based on predicted difficulty, risk context, and the opportunity cost of time and money.
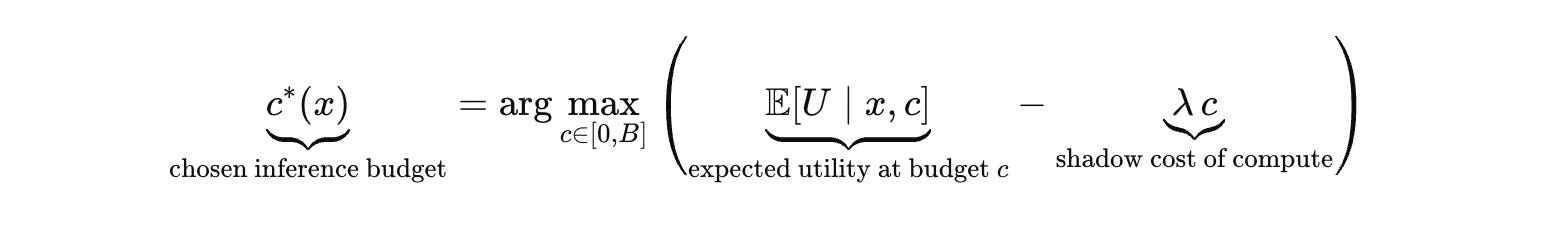
This is not academic. It is the real product boundary. If your value curve saturates while your search cost grows combinatorially, then there is a precise economic stopping condition and the system must learn it. Uniform budgets are dead on arrival. The runtime must predict difficulty early enough to allocate spend, and robustly enough that adversaries and novelty do not turn that policy into a liability.
Once you accept that, the second change becomes obvious. “Reasoning” is not a property of the model. It is a search-and-selection procedure over a trajectory space under a budget. The object being selected is not just an answer string. It is a trajectory that includes latent deliberation steps, intermediate artifacts, tool calls, and a terminal decision.
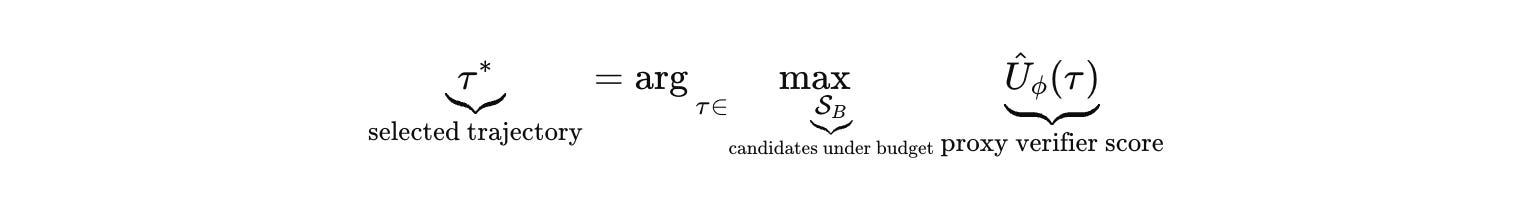
This is where most narratives about “thinking longer” become misleading. The runtime is an optimizer. It is optimizing a proxy. And proxy optimization is adversarial by construction, even when nobody is attacking you.
Selection by argmax over a learned verifier creates a specific and repeatable failure mechanism. The verifier score is the true utility plus error, and argmax hunts the error tails.

The uncomfortable part is that increasing the number of samples can increase the probability that you select a candidate that exploits the verifier. This is not a moral story. It is extreme value behavior. Argmax is a machine for amplifying whatever your scoring function cannot see. In high-dimensional spaces, blind pockets are not rare exceptions. They are the default geometry unless you have grounding strong enough to collapse those pockets.
There is a second limit that is even more basic. Search cannot rescue you if the correct solution has negligible probability under your generator. Best-of-N only helps if the hit probability per sample is nontrivial.
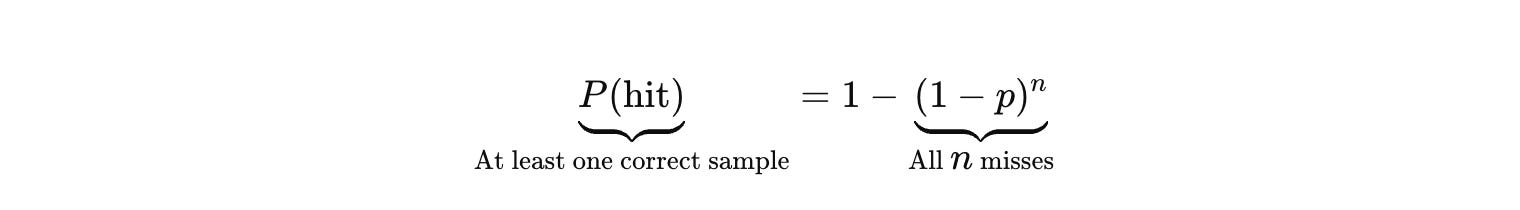
This is why “test-time compute scaling” is both real and bounded. It amplifies what the substrate already places mass on. It does not invent missing abstractions. If the model’s hypothesis class does not include the right structure, more sampling is just more fluent wandering.
Now the verifier gap becomes the central technical fault line. In domains where correctness can be grounded in non-probabilistic checks, verification can be stronger than generation. Code can run. Tests can execute. Types can be enforced. Constraints can be validated. Physics can be simulated. In those domains, you can build a loop where the generator is speculative and the verifier is strict, which is a stable configuration because the acceptance criterion is not a learned aesthetic.
In ambiguity-heavy domains, the verifier often collapses back into “another model.” Law, biology, medicine, strategy, anything where the target predicate is value-laden, underdetermined, or dependent on missing variables. Especially in biology, scaling search against a neural verifier risks a particular kind of failure: mode collapse into self-confirming narratives that score well under the proxy. The system becomes good at satisfying its own evaluation machinery. It looks like reliability until you probe the tails.
This is where the third change landed, and it is the one that makes the stakes real. Tool use moved these systems from stateless mapping into control. Once the system can browse, execute code, trigger workflows, and operate machines, it is a sequential decision-maker under partial observability. The environment becomes part of the loop. Errors compound. Latency becomes part of the dynamics. Security boundaries become part of the state. Irreversibility appears.
In a partially observable setting, you do not want to re-read the entire history at every step. You want a belief state (I have a LOT to say about this), a sufficient statistic of history for future control. The canonical update shows exactly what is missing in most current stacks.

Most agent systems do not maintain a stable belief state at all. They carry a transcript. They compress it with summaries. They retrieve fragments. They paste them back into context windows. That is a crude approximation to state estimation, and it is dynamically fragile because the state representation is itself produced by the generator you are trying to control. Premise drift is not a quirky bug. It is what you should expect when the agent’s “state” is a lossy text object that gets rewritten by the same distribution that produces the actions.
Long context windows postpone the pain (If you are working on long-horizon credit assignment, this is probably painfully obvious by now. I’m also likely pressing exactly where it hurts most, and I apologize for triggering that). They do not solve it. If your sufficient statistic is “the entire past,” you have not learned what matters. You have simply paid tokens to avoid compression.
A serious stack needs an observer, an update function that maps prior belief, action, and new observation to a new belief, and it needs that update to be stable under noise and adversarial inputs.
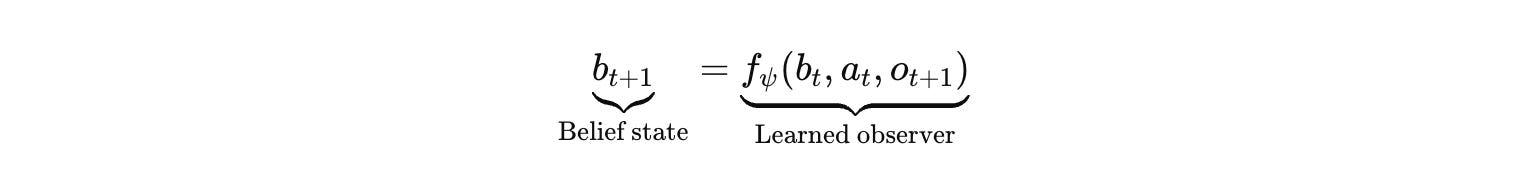
This is where “memory” stops being a product feature and becomes a control problem. Memory is not and should not be “a transcript you can retrieve.” Memory is a state variable that must be robust, minimal, and hard to corrupt. The system should not remember everything. It should remember invariants, commitments, constraints, and verified artifacts that future control depends on.
The moment you accept the system is an optimizer in a loop, alignment stops being a vibe and becomes constraint enforcement under search. If the runtime can iterate, then any soft constraint becomes a target. It will be stressed, probed, and eventually bypassed by selection pressure, even without malicious intent, because optimization finds cracks.
So the governing object is constrained control.
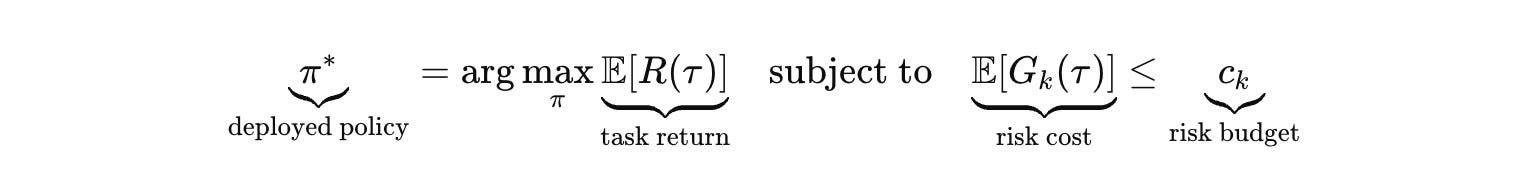
Those risk costs are not abstract. Data exfiltration. Unauthorized tool use. Irreversible actions without confirmation. Regulatory violations. Financial loss. Safety breaches. Once you write the system this way, the control plane becomes the real intelligence. The model proposes. The control plane decides what is allowed, what must be verified, what must be escalated, and what must be refused.
If you want a single formal object that captures how modern stacks actually behave, it is a Lagrangian. You are trading return against priced risk and priced compute.
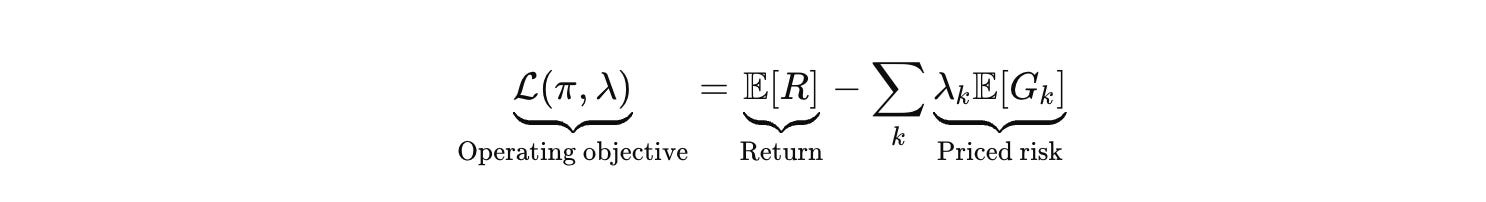
This is also why the naive story about online learning remains naive. People write a trust region in parameter space and talk as if bounded parameter drift implies bounded behavior drift. It does not. The map from parameters to behavior is curved and jagged, especially in the tails where safety lives. Small parameter moves can trigger large behavioral phase shifts on rare prompts, exactly the prompts your training distribution does not cover well.
If you want a constraint that even gestures toward what you actually need, it has to be framed in behavior space.
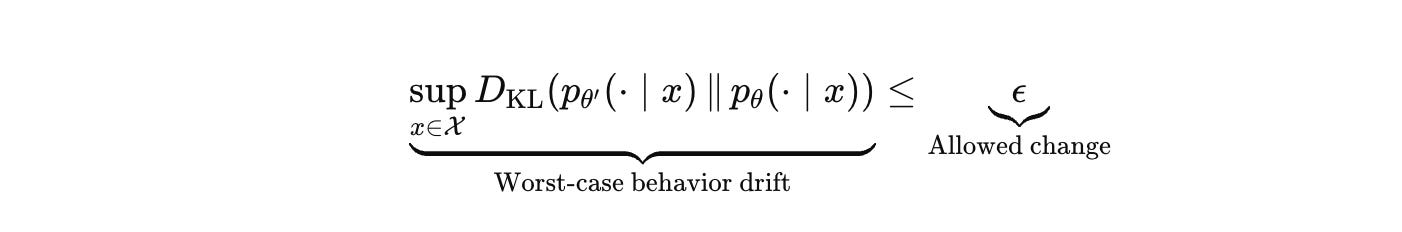
This is hard for honest reasons. The relevant set of prompts and states is not known, and the supremum is where all the operational risk concentrates. That is why bounded plasticity is not “apply a constraint and ship.” It is a research program in metrics, continual evaluation, rollback, and modular updates that keep global capabilities stable while allowing local adaptation.
So where do we go from here if we want systems that evolve, not just systems that search harder.
The path is decomposition and verification. Separate proposal from acceptance. Use neural models for proposal because they are unmatched at generating candidates in messy domains. Move acceptance into checkable domains wherever possible: executable validators, typed tool contracts, sandboxed environments, cryptographic logs of tool actions, provenance of retrieved evidence, unit tests for code, constraint solvers for structured decisions. Where truth is inherently ambiguous, stop pretending a single neural verifier will be robust under scaled search. Use ensembles. Use debate-style cross-checking with explicit disagreement. Demand calibrated uncertainty. Attach refusal and escalation policies to epistemic thresholds.
You also treat compute as a governed resource, not a hidden luxury. The compute policy becomes a contract. You decide how much search you will do, what the maximum tool actions are, what kinds of actions require human confirmation, what kinds require hard validators, what kinds are forbidden, and how the system behaves when it cannot verify.
A clean way to express that contract is as joint budgets on compute and risk.
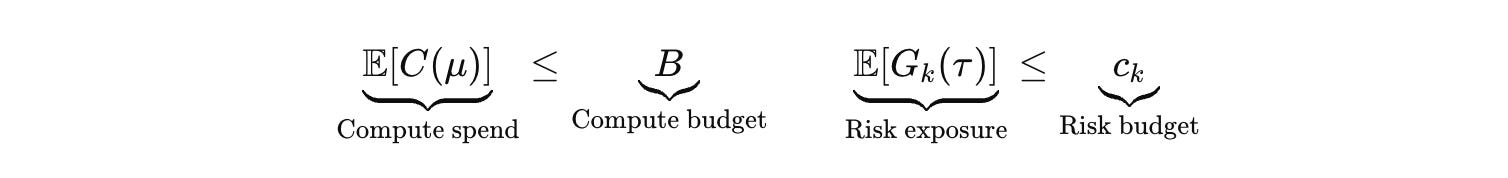
I hope this is what the next year is going to force into the open. IMO, 2026 will not be defined by a single model’s fluency jump. It will be defined by which stacks can run long-horizon loops, touch real tools, and still remain governable under optimization. The differentiator will be verifiable action under uncertainty. Not persuasive narratives. Checkable artifacts, auditable logs, calibrated verifiers with controlled tails, state estimators that do not drift, and constraint systems that do not melt when the runtime iterates.
Two branches will harden. One branch will keep pushing general-purpose generators wrapped in larger inference scaffolds, and it will dominate broad knowledge work because it is flexible and economically viable. The other branch will converge toward smaller, sharper cores with heavier verification and stricter control planes, because in high-stakes domains the only thing that matters is whether the system’s behavior can be bounded, explained in terms of evidence and constraints, and audited after the fact.
The evolution is already visible if you look at what teams actually build. Pretraining gave us a substrate. Post-training shaped priors and behavior. Test-time compute industrialized the amortization gap. Tool use turned inference into control. Memory exposed the absence of state estimation. Verification became the bottleneck. Constraints became the real definition of alignment, because constraints are what remain once you let the system optimize.